OpenAI推出GPT-4o,视频语音交互功能惊人
今天凌晨1:00(当地时间5月13日10:00),OpenAI举行了名为「春季更新」的线上发布会,宣布推出GPT-4的升级款模型GPT-4o。
发布会要点
1.新的 GPT-4o 模型:打通任何文本、音频和图像的输入,相互之间可以直接生成,无需中间转换
2.GPT-4o 语音延迟大幅降低,能在 232 毫秒内回应音频输入,平均为 320 毫秒,这与对话中人类的响应时间相似。
3.GPT-4o 向所有用户免费开放
4.GPT-4o API,比 GPT 4-Turbo 快 2 倍,价格便宜 50%
5.惊艳的实时语音助手演示:对话更像人、能实时翻译,识别表情,可以通过摄像头识别画面写代码分析图表
6.ChatGPT 新 UI,更简洁
7.一个新的 ChatGPT 桌面应用程序,适用于 macOS,Windows 版本今年晚些时候推出
GPT-4o 的强大在于,可以接受任何文本、音频和图像的组合作为输入,并直接生成上述这几种媒介输出。
这意味着人机交互将更接近人与人的自然交流。
GPT-4o 可以在 232 毫秒内回应音频输入,平均为 320 毫秒,这接近于人类对话的反应时间。此前使用语音模式与 ChatGPT 进行交流,平均延迟为 2.8 秒(GPT-3.5)和 5.4 秒(GPT-4)。
它在英文和代码文本上与 GPT-4 Turbo 的性能相匹敌,在非英语语言文本上有显著改进,同时在 API 上更快速且价格便宜 50%。

而与现有模型相比,GPT-4o 在视觉和音频理解方面表现尤为出色。
1,你在对话时可以随时打断
2,可以根据场景生成多种音调,带有人类般的情绪和情感
3,直接通过和 AI 视频通话让它在线解答各种问题
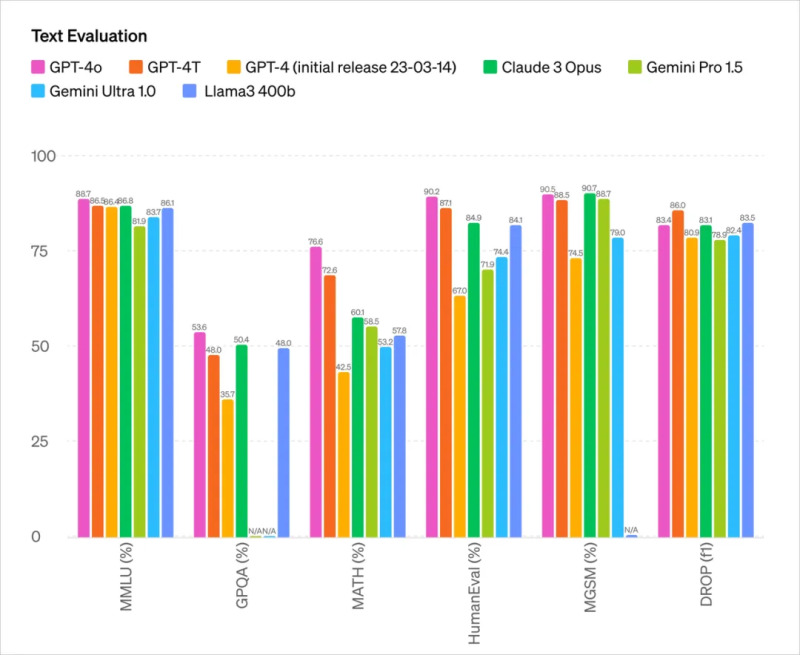
从测试参数来看,GPT-4o 主要能力上基本和目前最强 OpenAI 的 GPT-4 Turbo 处于一个水平。
此前的 AI 语言助手无法很好处理这些问题,在对话的三个阶段每一步都有较大延迟,因此体验不佳。同时会在过程中丢失很多信息,比如无法直接观察语调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。
当音频能直接生成音频、图像、文字、视频,整个体验将是跨越式的。
GPT-4o 就是 OpenAI 为此而训练的一个全新的模型,而要时间跨越文本、视频和音频的直接转换,这要求所有的输入和输出都由同一个神经网络处理。
而更令人惊喜的是,ChatGPT 免费用户就能使用 GPT-4o 可以体验以下功能:
1,体验 GPT-4 级别的智能
2,从模型和网络获取响应
3,分析数据并创建图表
4,聊一聊你拍的照片
5,上传文件以获取摘要、写作或分析帮助
6,使用 GPTs 和 GPT Store
7,通过 Memory 构建更加有帮助的体验
2、如对本稿件有异议或投诉,请联系:info@4Anet.com